https://docs.oracle.com/javase/tutorial/essential/concurrency/forkjoin.html
前言
理解这个框架前,我们需要知道这个框架设计的目标是为了解决什么问题?
为什么不可以用已有的框架来解决?
举例说明:对一个数组进行求和操作,如果这个数组非常大,我们会选择分段求和最后汇总
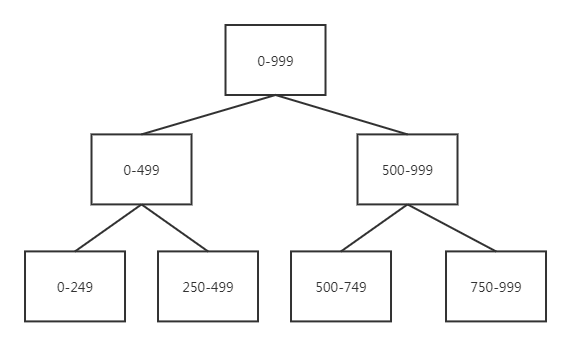
上图所示,0-999表示数组的下标,如果使用ThreadPoolExecutor创建线程池,可以考虑一下分割成上面的任务需要多少个线程。这里需要用到7个线程来实现求和,如果再分割多次,最后需要的线程会很多,显然不是我们所想要的。
为了满足我们的需求,Java从JDK7开始引入了Fork/Join框架来解决这类问题,利用多个处理器,是为可以递归分解为较小部分的工作而设计的。目标是使用所有可用的处理能力来增强应用程序的性能。
Fork/Join是ExecutorService接口的实现(这个接口用来实现线程池的,譬如我们常用的ThreadPoolExecutor),与其他实现ExecutorService的线程池一样,Fork/Join框架将任务分配给线程池中的工作线程。
与其他线程池不同的是,它使用了工作窃取算法(work-stealing),工作用尽的工作线程可以从其他仍很忙的线程中窃取任务。举个例子,0-499这个线程的子线程都计算完了,500-999子线程还在计算500-749,如果0-499这个线程等待500-999这个线程返回结果再去汇总这样会浪费资源,工作窃取算法会使执行0-499这个线程执行750-999,这样可以提高效率。
Fork/Join核心类
ForkJoinPoolForkJoinTaskRecursiveActionRecursiveTask